Test data infrastructure
nf-neuro provides an infrastructure to host and distribute test data, freely available to all contributors. This infrastructure is composed of three elements :
- A webserver hosting data packages, versioned using the DVC framework.
- A Nextflow subworkflow, LOAD_TEST_DATA, that downloads, caches and unpacks those data packages.
- A VS Code extension, Test Data Explorer, to browse test data packages, inspect their content and download them.
Test Data Explorer extension
Section titled “Test Data Explorer extension”[If working in the devcontainer, the extension is already installed and setup for you] Else, go to the Extension Marketplace and install it. You’ll find the extension under the name Test Data Treeview.
Once installed, a new tab section will appear in the Explorer Panel.
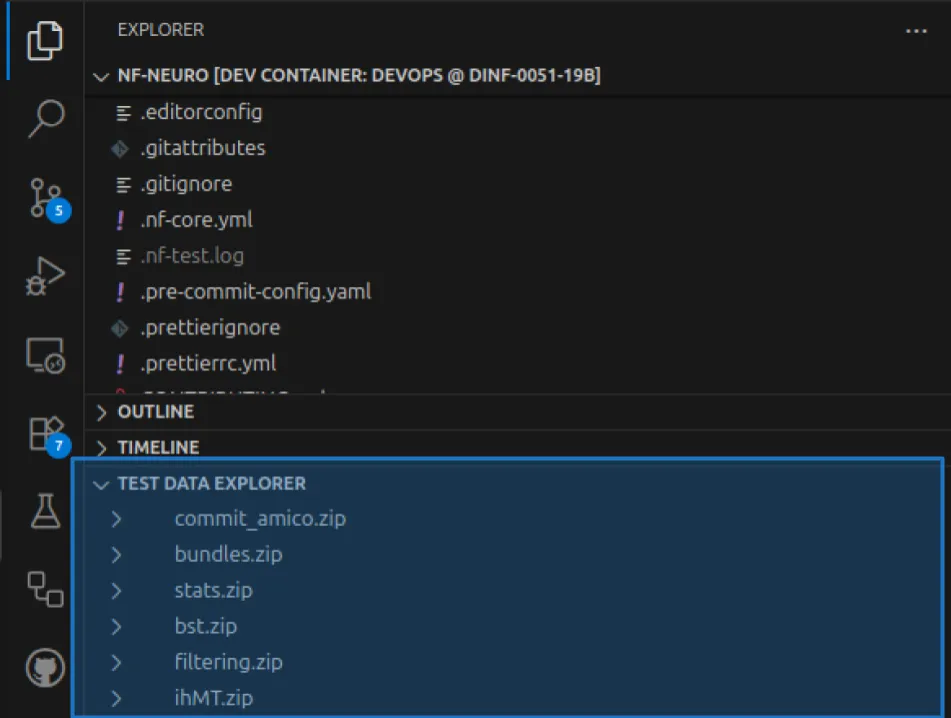
Click on the arrow icon on the right of an archive name to show its content. You might have to wait a bit for the archive to download locally.
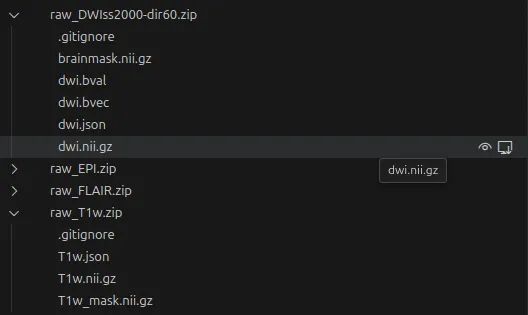
Hovering on a file name will display some options to interact with it :
- You can Display the files content
in the VSCode Editor Area.
- VSCode will select the best suited editor depending on the file type.
- For example, Nifti images are opened in the 3D viewer Niivue.
- You can Copy the file from cache to any location on your machine.
Usage outside of nf-neuro
Section titled “Usage outside of nf-neuro”By default, the extension is configured to work with the content of the nf-neuro repository. However, you can alter its configuration and use it to browse data organized in archives from any repository. You only need two things for the extension to work :
- A webserver hosting the data archives and exposing them as
httplinks. - A json file listing the archives and location on the webserver.
The json file contains a single object, a dictionary with archives’ names as keys and their location on the webserver as values :
{ "archive1": "path/to/archive1.zip", "archive2": "path/to/archive2.zip"}For flexibility, the base URI of the webserver is not hardcoded in the file, but provided as a VSCode setting. Use the configuration options below :
| Setting | Description | Default |
|---|---|---|
| testDataExplorer.dataserver | Base URI to the data server (without protocol) | |
| testDataExplorer.serverdatalocation | Subpath to the data location on the server (will be append to the dataserver URI) | |
| testDataExplorer.localListingLocation | Path to the local JSON file listing the archives |
LOAD_TEST_DATA subworkflow
Section titled “LOAD_TEST_DATA subworkflow”The LOAD_TEST_DATA subworkflow not only downloads and unpacks test data archives, but also caches them locally to prevent unnecessary re-downloads and preserve bandwidth. To use it, include it in your main.nf subworkflow file or main.nf.test test file :
include { LOAD_TEST_DATA } from '../load_test_data/main'include { LOAD_TEST_DATA } from '../../load_test_data/main'include { LOAD_TEST_DATA } from '../../../../subworkflows/nf-neuro/load_test_data/main'include { LOAD_TEST_DATA } from '../../../../../subworkflows/nf-neuro/load_test_data/main'The workflow has two inputs :
- A channel containing a list of package names to download.
- A name for the temporary directory where the data will be put.
To call it, use the following syntax :
archives = Channel.from( [ "<archive1>", "<archive2>", ... ] )LOAD_TEST_DATA( archives, "<directory>" )The archives contents are accessed using the output parameter of the workflow
LOAD_TEST_DATA.out.test_data_directory. To define actual test inputs from
it, use the .map operator :
input = LOAD_TEST_DATA.out.test_data_directory .map{ test_data_directory -> [ [ id:'test', single_end:false ], // meta map file("${test_data_directory}/<file for input 1>"), file("${test_data_directory}/<file for input 2>"), ... ] }Then, feed it to your subworkflow as follows :
preproc_A( input )DENOISING_ALGOA( input )