Running the pipeline
Choosing a profile
Section titled “Choosing a profile”Some sf-tractomics core functionalities are accessed and selected using profiles and arguments.
Processing profiles:
-
-profile gpuActivate usage of GPU accelerated algorithms to drastically increase processing speeds. Currently only uspports nvidia GPU. Accelerations for FSL Eddy and Local tractography are automatically enabled using this profile.
-
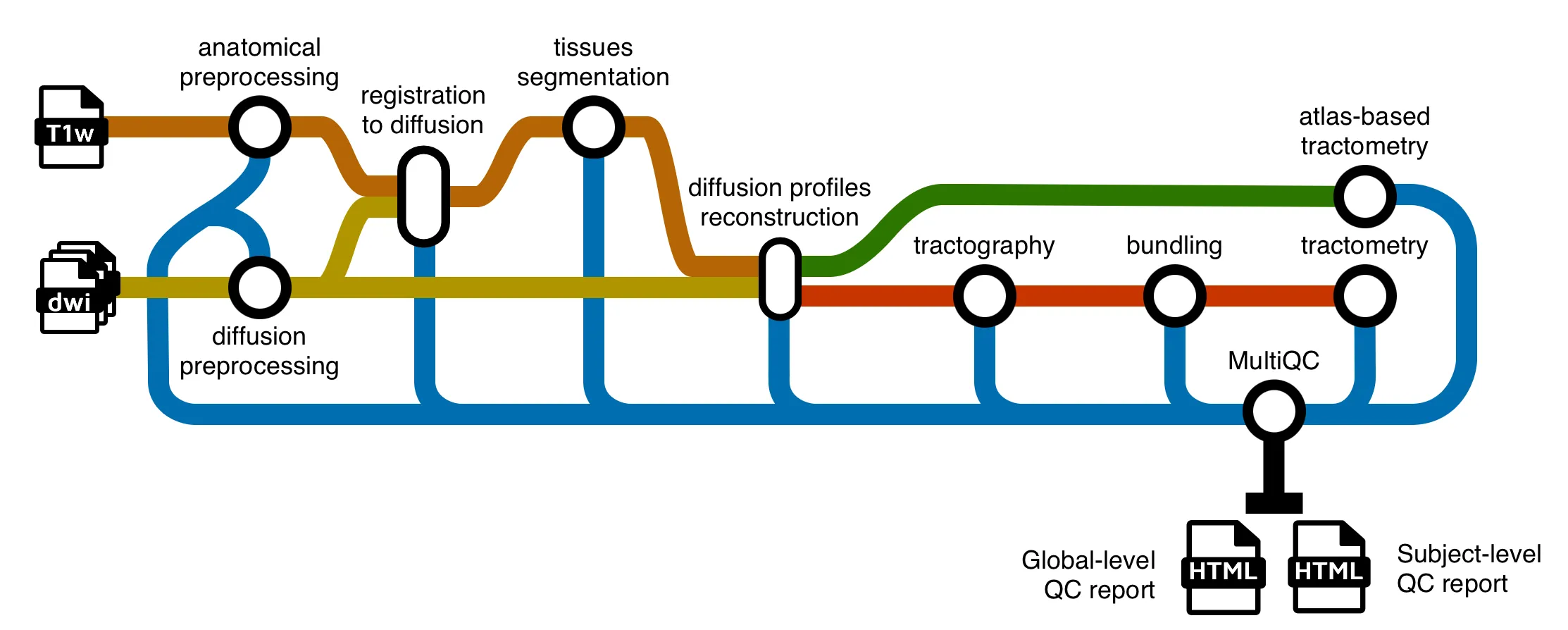
-profile full_pipelineRuns the full sf-tractomics pipeline from end-to-end, with all options.
Configuration profiles:
-
-profile docker(Recommended):Each process will be run using Docker containers.
-
-profile apptainer(Recommended):Each process will be run using Apptainer images.
-
-profile arm:Made to be use on computers with an ARM architecture (e.g., Mac M1,2,3,4). This is still experimental, depending on which profile you select, some containers might not be built for the ARM architecture. Feel free to open an issue if needed.
-
-profile slurm:If selected, the SLURM job scheduler will be used to dispatch jobs.
Using either -profile docker or -profile apptainer is highly recommended, as it controls the version of the software used and ensure reproducibility. While it is technically possible to run the pipeline without Docker or Apptainer, the amount of dependencies to install is simply not worth it.
Typical command-line
Section titled “Typical command-line”The typical command for running the pipeline is as follows:
nextflow run scilus/sf-tractomics -r 0.1.0 --input <input_directory> --outdir ./results -profile docker -resume -with-report <report_name>.htmlThis will launch the pipeline with the docker configuration profile, will run preprocessing, alignment of anatomy in diffusion space,
reconstruct diffusion profiles (DTI and fODF) and perform tracography (local and particle filtering algorithms). There are only 3 parameters
that need to be supplied at runtime:
-
--input: for the path to your BIDS directoryFor more details on how to organize your input folder, please refer to the inputs section.
-
--outdir: path to the output directoryWe do not specify a default for the output directory location to ensure that users have total control on where the output files will be stored, as it can quickly grow into a large number of files. The recommended naming would be something along the line of
sf-tractomics-v{version}where{version}could be0.1.0for example. -
-profile: profile to be run and container system to usesf-tractomicsprocessing steps was designed in profiles, giving users total control on which type of processing they want to make. One caveat is that users need to explicitly tell which profile to run. This is done via the-profileparameter. To view the available processing profiles, please see this section -
-resume: Enablesnextflowcaching capabilities.This is a core
nextflowarguments. It enables the resumability of your pipeline. In the event where the pipeline fails for a variety of reasons, the following run will start back where it left off. For more details, see the corenextflowarguments section. -
-with-report: Enablesnextflowcaching capabilities.This is a core
nextflowarguments. It enables the html report of your pipeline. For more details, see the corenextflowarguments section.
Note that the pipeline will create the following files in your working directory:
Directorywork/ # Nextflow working directory
- …
- .nextflow_log # Log file from Nextflow
Directorysf-tractomics-v0.1.0/ # Results location (defined with —outdir)
- pipeline_info # Global informations on the run
- stats # Global statistics on the run
Directorysub-01
… # Other entities like session
Directoryanat/ # Clean T1w in diffusion space
- …
Directorydwi/ # All clean DWI files, models, tractograms, …
Directorybundles/ # Extracted bundles when using bundling
- …
Directoryxfm/ # Transforms between diffusion and anatomy
- …
- … # Other nextflow related files
Using the params.yml file
Section titled “Using the params.yml file”If you wish to repeatedly use the same parameters for multiple runs, rather than specifying each flag in the command, you can specify these in a params file.
Pipeline settings can be provided in a yaml or json file via -params-file <file>.
The above pipeline run specified with a params file in yaml format:
nextflow run scilus/sf-tractomics -r 0.1.0 -profile docker -params-file params.yamlwith:
input: '<input_directory>/'outdir: './results/'<...>Reproducibility
Section titled “Reproducibility”It is a good idea to specify the pipeline version when running the pipeline on your data. This ensures that a specific version of the pipeline code and software are used when you run your pipeline. If you keep using the same tag, you’ll be running the same version of the pipeline, even if there have been changes to the code since.
First, go to the scilus/sf-tractomics releases page and find the latest pipeline version - numeric only
(eg. 0.1.0). Then specify this when running the pipeline with -r (one hyphen) - eg. -r 0.1.0. Of course, you can switch to another version by changing
the number after the -r flag.
This version number will be logged in reports when you run the pipeline, so that you’ll know what you used when you look back in the future. For example, at the bottom of the MultiQC reports.
To further assist in reproducibility, you can use share and reuse parameter files to repeat pipeline runs with the same settings without having to write out a command with every single parameter.
Core nextflow arguments
Section titled “Core nextflow arguments”-profile
Section titled “-profile”Use this parameter to choose a configuration profile. Profiles can give configuration presets for different compute environments.
Several generic profiles are bundled with the pipeline which instruct the pipeline to use software packaged using different methods (Docker, Singularity, and Apptainer) - see below.
The pipeline also dynamically loads configurations from https://github.com/nf-core/configs when it runs, making multiple config profiles for various institutional clusters available at run time. For more information and to check if your system is supported, please see the nf-core/configs documentation.
Note that multiple profiles can be loaded, for example: -profile tracking,docker - the order of arguments is important!
They are loaded in sequence, so later profiles can overwrite earlier profiles. For a complete description of the available profiles, please see this
section.
-resume
Section titled “-resume”Specify this when restarting a pipeline. Nextflow will use cached results from any pipeline steps where the inputs are the same, continuing from where it got to previously. For input to be considered the same, not only the names must be identical but the files’ contents as well. For more info about this parameter, see this blog post.
You can also supply a run name to resume a specific run: -resume [run-name]. Use the nextflow log command to show previous run names.
-with-report
Section titled “-with-report”Nextflow can create an HTML execution report: a single document which includes many useful metrics about a workflow execution. The report is organised in the three main sections: Summary, Resources and Tasks.
Specify the path to a specific config file (this is a core Nextflow command). See the nf-core website documentation for more information.